

Most ChatGPT SEO advice says the same four things. Structure your content well. Add schema markup. Let GPTBot crawl your site. Build authority. That advice is not wrong. It is just useless on its own, because it ignores the one thing that actually determines whether you get cited: ChatGPT and Perplexity do not pick their sources the same way, and almost every guide in the SERP treats them as if they do.
The sites that appear consistently as AI citations are doing something specific. Nine patterns separate them from the ones that followed all the generic advice and remained invisible. They are not secret. But they are concrete enough that you can check your own site against all nine this afternoon and know, within an hour, where you stand.
This guide covers the real mechanics behind how each platform selects sources, then walks through every pattern with enough detail to act on. If you have already read two or three articles that told you to "write high-quality content and use structured data," this is the one that explains what that actually looks like.
TL;DR: ChatGPT SEO means earning citation by ChatGPT's browsing tool, which pulls from Bing's index and applies brand recognition weighting. Perplexity SEO means earning citation by Perplexity's Sonar model, which weights recency, primary-source authority, and Google ranking as a prerequisite. The structural patterns that win citations on both platforms overlap significantly, but the source-selection mechanics differ enough that treating them as one job leaves obvious gaps. The nine patterns below apply to both, with platform-specific notes where the approach diverges.
What ChatGPT SEO actually is (and why it is not the same job as Perplexity SEO)
ChatGPT SEO is the practice of making your content reliably citable by ChatGPT's browsing and retrieval systems. It is distinct from traditional search ranking because the source-selection mechanism is fundamentally different: no ranked list, no human click, just an AI deciding whether to name you in its answer.
Perplexity SEO is the practice of appearing as a cited source in Perplexity's real-time responses. It relies on Perplexity's Sonar retrieval model, which has its own weighting for recency, primary-source authority, and original content, and treats Google ranking as a prerequisite rather than an afterthought.
They sound similar. They are not the same job.
Traditional Google SEO earns a position in a ranked list that a human browses and clicks. Both AI citation channels are different: they select a named source and weave your information into a generated answer. The reader may never visit your site. What they get is your information, attributed to you, inside the AI's response. That is a different kind of visibility, and it requires a different approach to earn.
Neither replaces Google. Both sit on top of it. The businesses that get this right treat answer engine optimisation as a third channel, not a replacement for the first two.
If you want the strategic picture of how GEO differs from SEO and where each fits, that post covers the territory. This guide focuses on the nine patterns that make the difference at the implementation level.
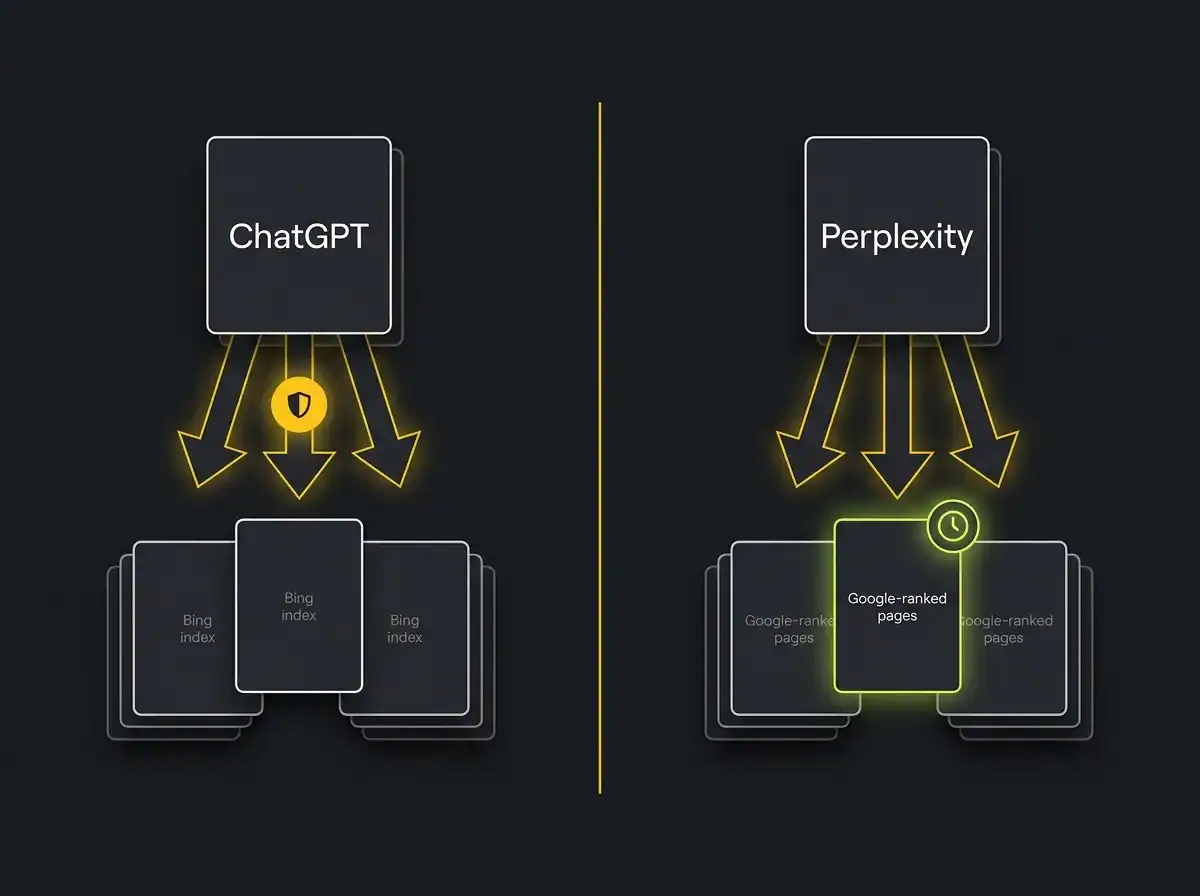
How ChatGPT actually picks the sources it cites
ChatGPT's browsing tool runs on Bing's index. That is the foundation, and it is the most frequently missed prerequisite in every guide on this topic.
If your pages are not indexed in Bing, ChatGPT's real-time browsing cannot find them. Full stop. It does not matter how well structured the content is, how many schema types you have applied, or how long the page has been live on Google. Bing indexation is a separate process. Many UK businesses that rank well in Google have pages Bing has never seen, because they have never submitted a sitemap to Bing Webmaster Tools and never checked.
Beyond the index, ChatGPT applies brand recognition heuristics when selecting sources. Brands with a significant presence in its training data, including third-party mentions in named publications and established knowledge databases, tend to get cited more frequently than technically-well-built pages from sites with no external footprint. A site that never appears in any third-party context starts at a disadvantage, regardless of how clean its markup is.
The training data layer matters too, even on queries where ChatGPT browses. If your brand has a presence in the training corpus via publications, review platforms, and industry databases, it carries credibility into responses. That is why authority-building is not just a Google tactic. It feeds the AI layer directly.
Allowing GPTBot in your robots.txt, as OpenAI's GPTBot documentation explains, is the minimum condition for ChatGPT to crawl your pages. It is the floor, not the ceiling. Treating it as the finish line is why many technically-compliant sites remain invisible.
AI traffic converts at significantly higher rates than standard organic, which makes citation visibility worth pursuing properly. A visitor who arrives from a ChatGPT citation has already been told, by the AI they trust, that your content is a credible source. They arrive in a different frame of mind.
How Perplexity actually picks the sources it cites
Perplexity is meaningfully different from ChatGPT in its source-selection approach. This is the part most guides either miss entirely or cover in one sentence.
Perplexity's Sonar model uses real-time search to retrieve sources before generating its response. Its approach uses Google ranking as a strong prerequisite: pages that do not rank on Google for the relevant query are significantly less likely to appear in Perplexity's citation pool. You are not chasing Perplexity citations instead of Google ranking. You are doing traditional SEO well enough to be in Perplexity's consideration set, and then doing additional work to be selected from that set.
Recency is weighted more aggressively by Perplexity than by ChatGPT across most query types. Pages refreshed with substantive new content within the last few weeks reportedly receive a meaningful lift for time-sensitive topics. Older pages, even authoritative ones, get deprioritised. This creates a different operational requirement than ChatGPT: Perplexity citation requires active content maintenance, not just a well-built archive.
Perplexity also shows a strong preference for primary-source content. Original data, original framing, named research. A page that summarises what three other sites have said is less likely to be cited than a page that contributes something specific those sites do not have. Perplexity's extraction model is designed to pull clean atomic answers from pages, so your content structure needs to serve that extraction mechanism directly.
Here is how the two platforms compare across six dimensions.
-
Source index: ChatGPT uses Bing's index via its browsing tool. Perplexity uses real-time search with Google ranking as a strong prerequisite.
-
Recency weighting: ChatGPT weights recency selectively, mainly on time-sensitive queries. Perplexity weights recency aggressively across most query types.
-
Authority signal: ChatGPT gives significant weight to brand recognition and training data presence. Perplexity weights primary-source authority and original content above general brand recognition.
-
Citation format: ChatGPT tends to name sources inline within the generated answer. Perplexity shows a source panel alongside the response, making attribution more visible.
-
Depth preference: ChatGPT handles both shallow and deep content reasonably well. Perplexity's Sonar model appears to favour depth and original framing over thin list posts.
-
Content type: ChatGPT cites across content types. Perplexity shows a stronger preference for atomically-answered, structured content with BLUF responses.
Pattern 1: they let the AI crawlers in
This is the technical foundation. Most sites get it wrong not by intention but by never checking.
The robots.txt file is the gating mechanism. Sites that appear consistently as AI citations allow the following crawlers explicitly: GPTBot (ChatGPT's web crawler), OAI-SearchBot (OpenAI's search crawler), ChatGPT-User (the real-time browsing agent), ClaudeBot (Anthropic's crawler), and PerplexityBot (Perplexity's crawler). If you also want Gemini to access your content for AI features, Google-Extended needs an explicit allow rule too.
Each of these is a separate user agent. Blocking GPTBot does not block OAI-SearchBot. Allowing ClaudeBot says nothing about PerplexityBot. They need to be addressed individually. Most sites have a general allow-all rule that technically covers all of them, but it is worth verifying explicitly rather than assuming.
Bing indexation is the next check. Run your core URLs and recent posts through Bing Webmaster Tools and confirm they are indexed. For many UK businesses, there are gaps here: newer pages and blog posts that Google has already crawled but Bing has not, because the sitemap was never submitted to Bing or the crawl budget was never managed.
An llms.txt file is worth adding. Our post on what an llms.txt file actually does explains this properly, but the short version: it helps AI crawlers understand what your site contains and where to find the most relevant content. It does not instruct AI models to cite you. Treat it as a crawler-signalling tool, not a citation fix. Sites that added llms.txt and nothing else saw no meaningful change in citation frequency.
Pattern 2: they have stacked third-party authority signals
The sites that appear consistently as ChatGPT citations exist credibly outside their own domain. That is the distinction.
Active review profiles matter more than most owners expect. Brands with detailed, populated profiles on Trustpilot, Google Business Profile, G2, and Capterra tend to appear more frequently in AI citation pools than brands that have suppressed reviews or never claimed their profiles. The likely mechanism is straightforward: ChatGPT's training data includes these platforms, so a brand that appears there with genuine reviews becomes part of its established knowledge in a way that a brand with no external presence does not.
Named mentions in industry publications are the second layer. Not guest posts on tangential blogs. Named placements in publications with their own editorial credibility: trade press, national business media, professional associations. A mention in an FT feature, a CIM case study, or a relevant sector trade publication adds to brand signal density in a way that volume-driven guest posting does not.
Real author bios with verifiable credentials matter more in AI search than they do for traditional Google results. An article attributed to a named person with a professional profile and external recognition is structurally different, in how AI models evaluate it, from content attributed to "the marketing team." Named authorship is a proxy for the kind of primary-source authority that both Perplexity and ChatGPT say they prefer.
Pattern 3: they answer the question in the first 100 words of every section
This is the single biggest practical separator between cited and ignored content. It is also the one most often sacrificed by writers who want to build up to the point rather than lead with it.

The principle is BLUF: bottom line up front. Every section opens with the answer, not the setup. An AI's extraction model reads your content, identifies the most direct response to the query it is answering, and lifts it. If your most direct answer is buried in paragraph four after three paragraphs of context, the extraction model will either miss it or cite a competitor whose answer was in sentence one.
The before version: "When thinking about how to structure content for AI search, there are several factors worth considering. Content has historically been written with a specific audience in mind, and transitioning to a more AI-friendly approach requires understanding how these models process information before generating responses."
The after version: "AI citation tools extract the most direct answer to a query from the first sentence they encounter that matches the query intent. Open every section with that answer."
Same idea. Very different results when an LLM is deciding what to lift and attribute.
This does not mean every section becomes a dry Q&A. It means the opening sentence under each H2 is the answer, and the paragraphs that follow earn their place by adding depth, evidence, or context to it. The human reader reads for depth. The AI extracts from the top.
Pattern 4: they use structured comparisons, not buried prose
Both ChatGPT and Perplexity show a preference for content that makes comparisons easy to extract. A dense paragraph where the comparison is embedded in flowing prose forces the extraction model to parse what a clearly structured list makes obvious.
The structured comparison you saw earlier in this post, the six-dimension ChatGPT versus Perplexity breakdown, is an example of this in practice. A reader asking "what is the difference between ChatGPT SEO and Perplexity SEO" gets a cleaner citation from a structured key-value list than from a paragraph where those differences are woven into a narrative. The list is the citable thing.
Apply this wherever you make a comparison: pricing options, feature differences, platform behaviours, before-and-after examples. The structure does not need to be a visual table. A clearly formatted key-value list achieves the same extraction result and renders consistently across WordPress themes and preview tools. Keep it semantically clean so AI crawlers can parse the structure, not just read the text.
Pattern 5: they refresh content meaningfully every few weeks
Perplexity's recency bias is the sharpest example of why this pattern matters, but it applies to both platforms on time-sensitive queries.
A meaningful refresh is not changing the date in the meta. It is not adjusting two sentences to trigger a recrawl. A meaningful refresh adds new data, new examples, updated statistics, or a new section that reflects something that has genuinely changed. That is the kind of update Perplexity's model appears to recognise and reward with renewed citation priority.
Pages that have had substantive new content added within the last three to four weeks reportedly sit higher in Perplexity's citation pool for time-sensitive topics than equivalent but older pages. On evergreen topics the recency weighting is less aggressive, but it still applies when competing against a site that has refreshed more recently.
Article schema with the dateModified field should reflect when the content actually changed. If you are refreshing a page meaningfully every month, dateModified should move every month. An accurate dateModified is better than a false freshness signal, both for honesty and because platforms that can crawl the page history will notice when the stated date does not match the content.
The operational cost here is real. Running a meaningful refresh programme across fifteen or twenty pages every few weeks is not a Friday afternoon task for one person. It is one of the practical reasons that businesses running this at scale tend to treat it as a structured programme.
Pattern 6: they are heavy on named entities
Generic content gets ignored. Named content gets cited. That gap is larger than most people expect.

Named entities are specific, verifiable proper nouns: tool names, platform names, publication names, research institutions, named frameworks, named people. The difference between a paragraph that mentions "AI research" and one that mentions "Profound's analysis of ChatGPT citation patterns, BrightEdge's data on AI Overview source selection, and Otterly's weekly citation tracking" is the difference between content an LLM treats as generic and content it treats as authoritative.
A generic version: "Several studies have shown that AI tools prefer content from sites with strong authority signals and external recognition."
The named-entity version: "Research from Profound into ChatGPT citation patterns and separate analysis from BrightEdge on AI Overview source selection both point to third-party review platforms, specifically Trustpilot, G2, and Capterra, as meaningful authority signals for AI citation, alongside editorial coverage in named publications."
The second version is citable. It names sources. It names platforms. It gives the AI something it can attribute. The first version is a reasonable sentence that an AI will never quote because there is nothing specific to attach to.
Apply named entities throughout your content: ChatGPT, Perplexity, Claude, Gemini, Bing, GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot, Google-Extended, llms.txt, schema.org, FAQPage schema, Article schema, Yoast, Rank Math, Ahrefs, Semrush, Profound, Trustpilot, G2, Capterra. Where you discuss tools, name them. Where you reference research, name the source. Where you reference platforms, name the platform.
Pattern 7: they include original or specific data
Perplexity's primary-source preference is the clearest reason this pattern matters, but it applies to ChatGPT as well.
Sites that generate original data, whether through client surveys, proprietary audits, or named studies, appear more frequently in AI citations than sites that aggregate what other sites have already published. If you are the source of a data point, and other sites cite you for it, the AI traces that citation chain back and identifies you as the primary source. That is a powerful position to hold.
If you cannot generate original data, cite specific numbers from named sources rather than rounding or paraphrasing them. "47 per cent, according to Profound" is more citable than "roughly half." The named source plus the specific figure is the atomic fact an AI can lift and attribute.
UK-specific data has a real advantage that most content ignores. ONS figures, Companies House data, government sector statistics, and specialist research from bodies like LaingBuisson in healthcare represent genuinely primary-source material that most competitor content in any given niche, particularly US-origin content, does not include. If you are a UK business writing for a UK audience, those sources make your content distinctly citable in a pool that defaults to American statistics.
Pattern 8: they have a clean FAQ section answering the obvious follow-ups
FAQPage schema applied to a genuinely useful set of questions is one of the most reliable patterns for Perplexity citation, and solid for ChatGPT too. The key word is genuinely useful.
Perplexity's Sonar model appears to distinguish between FAQ sections that answer real follow-up questions and FAQ sections that exist to add keywords to the page. Four to six atomic Q&A pairs, each 40 to 80 words, answering what a real reader would actually ask after the main content, consistently outperforms a 15-question block where most answers are thin rewrites of the main text. The overstuffed FAQ block is also one of the patterns that contributed to Google's Helpful Content guidance, so the same behaviour hurts both channels.
The questions should map to People Also Ask results for your target keyword, combined with the top objections a reader would have after finishing the main post. For a post on ChatGPT SEO, those are questions like "is this the same as Google SEO," "how do I even know if it is working," and "do I need an llms.txt file." Questions a real reader would actually type.
FAQPage schema markup needs to be applied correctly: each Question object with a name and an acceptedAnswer with a text property. WordPress plugins including Yoast SEO and Rank Math both support this natively. Apply the schema, check it validates in Google's Rich Results Test, and move on.
Pattern 9: they monitor and adjust, weekly
The sites that sustain citation visibility run a weekly monitoring routine. The ones that ran a one-time technical fix and moved on tend to fall out of the citation pool within a month.
![]()
The monitoring routine is straightforward in concept. Five to ten category prompts, run across ChatGPT and Perplexity each week: "what are the best [service] providers in [region]," "who should I speak to about [topic]," "explain [subject] and give me examples." Track whether your brand appears, where it appears in the response, and which competitors are named when you are not.
Tools that support this at scale include Profound, Otterly, Geneo, and BrandRank.io, all of which track AI citation at brand level across multiple platforms. Manual monitoring is entirely valid for smaller sites and narrower topic areas. Run the prompts yourself, log the results in a spreadsheet, and track week-on-week changes.
When you find you are not cited at all, work through the checks in order. First, technical: is GPTBot allowed, are the relevant pages indexed in Bing, has the content been refreshed recently. Second, structural: do the pages open with BLUF answers, do they include named entities, do they have FAQPage schema. Third, authority: are there third-party review profiles, named publication mentions, and author bios supporting the content.
If all of those check out and you are still invisible, the issue is usually competitive authority, which takes longer to build and is harder to address without sustained effort over several months.
Free resource: AI Visibility Audit
The audit checks whether ChatGPT, Claude, and Perplexity cite your site today, against which prompts, and against which competitors. Most businesses run it and find gaps they did not know existed, because they have never had a structured way to check.
When ChatGPT SEO is worth running yourself, and when it warrants help
The DIY case is real for certain businesses. A specialist consultancy with a narrow topic focus, a founder who already writes, and a small competitor set can run an effective citation programme themselves. Run the technical checklist once, write BLUF-first content, maintain a refresh schedule, and monitor monthly. It is not complicated. It requires consistency.
The case for getting help is different. B2B businesses where ChatGPT and Perplexity already name competitors in response to queries about the service you offer have an urgency problem, not just a technical one. When an AI names your competitor to a prospect who has never heard of either of you, that prospect may never search further. That is a lost enquiry that does not show up in any traffic report.
Regulated industries where citation accuracy is non-negotiable, and businesses where the technical foundations (Bing indexation, schema, robots.txt, authority signals) need rebuilding before content work has any chance of working, are the clearest cases for a structured programme.
Working with an AI SEO agency means running this as a programme rather than a project: audit, technical fix, content structure, authority-building, and weekly monitoring, with results tracked properly and adjusted based on what the monitoring shows. The nine patterns in this guide are the components of that programme. Whether you run it yourself or have help running it depends on how much competitive urgency you are facing and whether you have the in-house time to sustain it.
Frequently asked questions
Is ChatGPT SEO the same as Google SEO?
No. Google SEO earns a position in a ranked list that a human browses and clicks. ChatGPT SEO earns a citation inside a generated answer, where the AI selects sources based on Bing indexation, brand recognition, and content structure rather than a ranking algorithm. The overlap is real: technical health, authority, and content quality matter for both. But the mechanisms are different enough that they need separate attention.
How do I check if ChatGPT cites my site?
Run the category prompts yourself: "who are the best [service type] providers in [region]," "what does [your topic] mean, give me examples." Log whether your brand appears, which pages are cited, and which competitors are named when you are not. For structured tracking, tools like Profound, Otterly, and BrandRank.io provide brand-level citation monitoring across ChatGPT, Claude, and Perplexity.
Do I need an llms.txt file?
It is worth adding, but it is not a citation fix. An llms.txt file helps AI crawlers understand what content is on your site and where to find it. It does not instruct AI models to cite you. Sites that added llms.txt and nothing else saw no meaningful change in citation frequency. The technical foundation, content structure, and authority signals have far more impact.
Is Perplexity SEO different from ChatGPT SEO?
Yes, in two important ways. Perplexity uses Google ranking as a prerequisite for source selection, so traditional SEO is the ticket in rather than an optional extra. And Perplexity weights recency more aggressively, which means content needs active maintenance to sustain citation frequency. The structural patterns, BLUF, named entities, schema, authority signals, apply to both platforms, but the operational requirements differ.
How long does ChatGPT SEO take to show results?
Technical fixes (robots.txt, Bing indexation, schema) can show results within a few weeks for pages that were previously invisible to AI crawlers. Content structure improvements typically influence citation frequency within one to three months, as platforms recrawl updated pages. Authority-building, review profiles, publication mentions, third-party links, takes longer, usually three to six months for meaningful impact, because it depends on external actions rather than changes to your own site.
The next step
You have read the patterns. The next 30 minutes worth doing is finding out where you actually stand.
The AI Visibility Audit checks whether ChatGPT, Claude, and Perplexity cite your site today, against which prompts, and against which competitors. Most businesses that run it find specific gaps they did not know existed: a competitor named in queries they assumed they owned, key pages invisible to Bing despite ranking on Google, or citation frequency that looks acceptable until you see the competitor comparison.
Knowing where you stand is the decision point. Some businesses find they are in reasonable shape and need a refresh programme to sustain it. Others find they are invisible on the queries that matter most and need to address the foundations before content work makes any difference.
For businesses thinking about Google and AI search together as part of a broader visibility strategy, our search visibility and traffic hub covers how both channels interact in practice.
The audit is free and takes about 30 minutes. The results are specific enough to act on the same day.
