
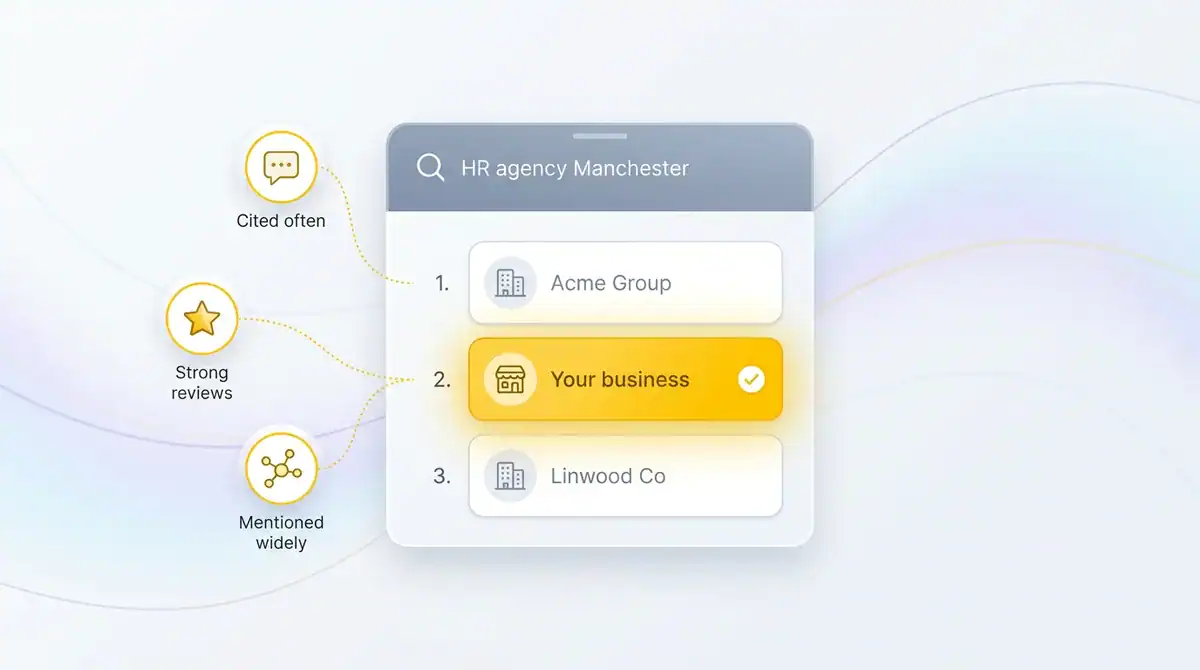
You type a category-level question into ChatGPT. Something like "recommended B2B consultancy for a mid-sized UK firm" or "best HR agency in Manchester." You have been running a solid SEO programme for two years. Your search visibility and traffic metrics look healthy. You press enter.
Four competitors come back. You are not one of them.
That is the LLM visibility gap. And the uncomfortable part is that your Google rankings had nothing to do with it. The model did not consult the first page of search results and pick the top-ranked site. It constructed an answer from its training data, live sources, and a set of associations about which brands are credible in your category. You were not in that picture.
This is the conversation we are having with UK service business owners right now. They have invested seriously in organic search and they are performing well by Google's own metrics. But when a potential client types a category prompt into ChatGPT, Claude, or Perplexity, they are invisible. The model names three or four competitors, frames them positively, and moves on. Sound familiar?
This post explains what LLM visibility actually measures, the five sub-metrics sitting underneath it, how to track it without a five-figure SaaS bill, and what a defensible score looks like for a UK service business at three different scales. This is not a tools roundup. The SERP is already full of those. This is the version for a firm that wants to know where it stands and what to do about it this quarter.
What LLM visibility actually measures
LLM visibility is the share of AI-generated answers in your category that mention or cite your brand, measured across the major models.
That is the definition. Worth sitting with for a moment.
It is not a position. It is not a ranking. It is not a score out of 100 produced by a tracking dashboard. It is the proportion of relevant AI answers, across a defined set of category-level prompts, in which your brand appears at all. Some brands score zero on their first audit. Category leaders score above sixty percent. Most UK service businesses, when they first measure, sit somewhere between five and thirty.
The distinction from traditional SEO visibility matters more than it first appears. SEO visibility measures where your pages appear on a results page and how often they earn a click. LLM visibility measures whether your brand appears inside a generated answer. Those are fundamentally different things. A model does not show the user a list and let them choose. It writes a paragraph, or a bulleted recommendation, or a conversational reply. Either your name is in it or it is not.
Presence inside an AI answer can mean three things, and the difference matters when you start tracking. A name mention is the model referencing your brand without a link. A citation is a mention that comes with a clickable source pointing to your domain. A recommendation is the model actively suggesting your brand as a solution to the user's specific problem. All three count as LLM visibility. They carry very different commercial weight.
ChatGPT, Claude, Perplexity, Gemini, and Google AI Overview each construct answers differently, draw on different sources, and update on different cycles. A brand visible on Perplexity can be nearly absent from ChatGPT. That variability is exactly why tracking across models matters rather than picking one platform and calling it done.
The five metrics that sit underneath LLM visibility
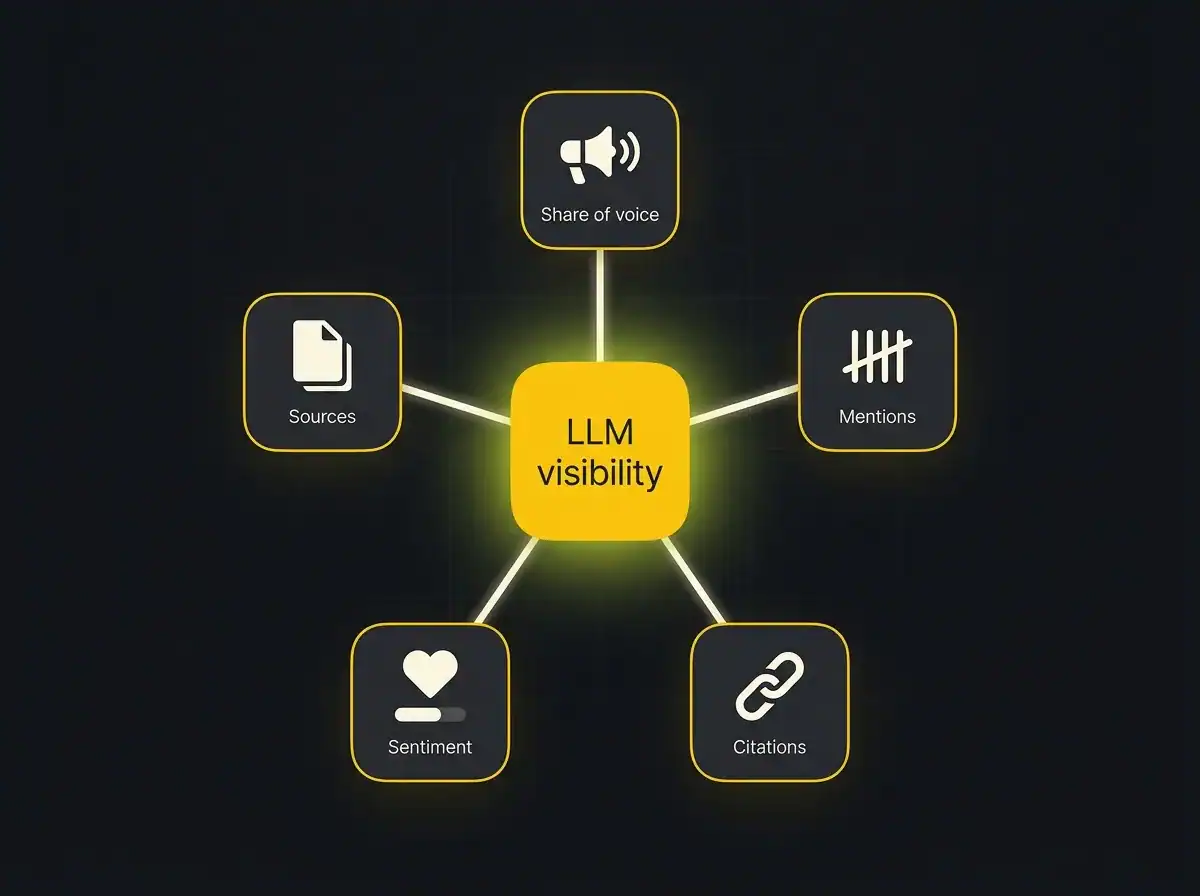
Most tracking tools and most articles on this subject present LLM visibility as a single number. It is not. There are five distinct sub-metrics, and understanding which one is moving tells you what is actually working or failing.
Share of model voice is the headline figure. Across all the category-level prompts you track, what percentage of AI answers mention your brand at all? This is the number that most closely parallels traditional SEO visibility scores, and it is the most useful metric for competitive benchmarking. If three competitors each appear in sixty percent of answers and you appear in ten percent, that gap is your problem statement.
Mentions is the raw count of brand appearances across your fixed prompt set. Share of model voice tells you the rate; mentions tells you the volume. Mentions are most useful for trend tracking month on month. A rising mentions figure against a flat share of voice figure means the models are answering more category prompts overall, which is useful context for interpreting a flat headline number.
Citations are mentions that come with a clickable source link to your domain. This is the most commercially valuable sub-metric, because a citation is what drives actual referral traffic. According to Backlinko's research on LLM citations, a disproportionate share of citations come from long-tail, specific-topic pages rather than homepages or high-authority service pages. What ranks does not predict what gets cited. If your citation rate is rising while share of voice stays flat, you are earning traffic from the small percentage of answers that do mention you. That is still a positive signal.
Sentiment captures the framing the model uses when it mentions your brand. Positive, neutral, negative, or sceptical. This is the metric most commonly skipped in DIY tracking workflows because it requires reading rather than marking a yes or no in a spreadsheet. It matters because a model that mentions you neutrally as "one option among several" is very different from one that positions you as the recommended choice. Paid tools automate sentiment scoring. Manual trackers have to read and judge each instance.
Sources are the specific URLs and domains the model is leaning on to construct its answers. This tells you which of your pages are doing the citation work, or, if you are not being cited, which competitor pages and third-party sources the model treats as authoritative for your category. Sources is the most useful diagnostic metric of the five. It tells you exactly where to direct content and PR work to shift the other four numbers.
Most DIY approaches track mentions and citations and stop there. Tracking all five gives you the picture you need to make deliberate improvements rather than guessing.
Why your Google rankings do not predict your LLM visibility

The most common assumption CT encounters is that solid Google performance gives a reasonable proxy for AI visibility. A decent domain, consistent rankings, a few years of published content. Surely some of that transfers?
Some of it does. Much of it does not.
Backlinko's research on LLM citations found that a disproportionate share of ChatGPT citations come from long-tail pages rather than high-traffic pages or pages with strong domain authority. The implication is striking. A page targeting a very specific question may get cited more frequently than a well-optimised pillar page that ranks strongly on Google, purely because the specific page gave the model a clear, atomic answer to a precise query. Domain authority, the currency most SEO programmes are built around, matters less in this context than topical clarity.
The mechanism is worth understanding at a basic level. Large language models ingest training data, retrieve live results on some queries, and re-synthesise answers. When they do that, they are pattern-matching on which sources have made clear, credible statements about a topic. A page that makes one specific claim precisely is more citable than a page that covers fifteen topics thoroughly. Named-entity associations also matter: if your brand name appears consistently alongside the category terms, problem descriptions, and named concepts in your space, models build stronger associations between your name and your positioning.
The commercial stakes are real. Research from Bain and separately from Semrush points to AI search growing its share of how professionals discover suppliers and services. Search Engine Land's coverage of the shift has been consistent: AI-generated answer presence on consideration-stage commercial queries is rising, and buyers are increasingly starting their supplier research in an AI chat rather than a search box. And AI traffic converts at a significantly higher rate than traditional search, because visitors arriving via an AI recommendation have already received an endorsement. They are verifying a decision, not beginning one.
A programme that won Google rankings will not automatically win AI citations. New work is required.
How to track LLM visibility without enterprise budget
![]()
The tracking tools for LLM visibility currently range from free manual work to £400 a month and above. For most UK service businesses, the right starting point is considerably closer to the free end.
The manual workflow suits any business with under roughly £2 million in annual revenue, or any business that wants a baseline before committing to a paid subscription. Build a fixed prompt set of 25 to 50 category-level questions. Run them across ChatGPT, Claude, Perplexity, and Gemini once a month. Log the results in a spreadsheet: prompt, model, brand mentioned yes or no, citation yes or no, sentiment, competitor names that appeared. Total time: two to four hours a month. Total cost: the price of a ChatGPT Plus or Claude Pro account you probably already have.
The prompt set itself needs thought. Mix four types of prompt to get meaningful data:
-
Category prompts: "best [service] in [location]" or "recommended [service] for [industry]"
-
Comparison prompts: "how does [your brand] compare with [competitor]"
-
Problem prompts: "how do I [specific problem your service solves]"
-
Recommendation prompts: "recommend a UK [service] provider for [specific need]"
A good 30-prompt set surfaces which parts of your positioning the models know well and which parts they have no picture of at all. That diagnostic value alone is worth the two hours.
Paid tools make sense when you need continuous monitoring, automated competitor benchmarking, or coverage across more models than you can run manually. The main options right now are: AccuLLM (UK-friendly, focuses on citation tracking, lower price point), Profound (US-built, strong on share of model voice, aimed at larger brands), LLMrefs (tracking across multiple models with source analysis), SE Ranking's AI Visibility Tracker (integrates with their existing SEO suite, useful if you are already a customer), Mangools AI Search Watcher (simpler feature set, accessible pricing), and LLM Pulse (specialises in citation and source data). None covers every model perfectly. Pricing changes frequently. Treat any figure here as a starting point rather than a fixed commitment.
The hybrid approach is what we actually recommend for UK service businesses at mid-market scale. Use a paid tool for trend tracking and competitive benchmarking, where the automation saves genuine time. Run your own manual prompt set monthly for the qualitative read: what does the model actually say about you, how does it frame your positioning, is the sentiment shifting. The automated tool catches movements in the numbers. The manual read catches things the tool does not score.
Free resource: AI Visibility Audit
If you want to know your current LLM visibility score before committing to a tracking workflow, our AI Visibility Audit runs your brand and up to three named competitors through a fixed prompt set across the major models, and returns a mention rate, citation rate, sentiment breakdown, and source analysis.
What good LLM visibility looks like for a UK service business
This is the section the SERP currently lacks.
Every piece of content ranking for this query either avoids setting a benchmark entirely, or sets one calibrated to enterprise SaaS brands with US market conditions. Neither is useful if you run a recruitment firm in Leeds or an accountancy practice in Bristol and want to know whether your score is a crisis or a starting point.
What follows are working heuristics from CT's audit work. They are not published industry benchmarks, because mature industry benchmarks for LLM visibility do not yet exist. Any agency claiming firm category benchmarks for this metric is over-claiming. These are the ranges we see across UK service business audits and the thresholds at which a score feels defensible versus genuinely concerning. David to confirm or adjust against the most recent audit data before this publishes.
Small UK service business (under £1 million turnover, single location). A mention rate of 15 to 25 percent on a 30-prompt category set is a meaningful baseline at this scale. You will not appear in most AI answers, and that is not a crisis. Larger, better-known brands dominate category prompts and that is expected. What matters is whether you appear at all on prompts where you have a genuine claim to relevance. A citation rate above five percent at this scale is encouraging and actionable. If you are sitting at zero citations across 30 prompts, that is the specific problem to solve first, before anything else.
Mid-sized UK service business (£1 million to £10 million turnover, multi-location or specialist team). A mention rate of 35 to 55 percent on category prompts is a reasonable target. You have enough published content, online presence, and external mentions that models should be picking you up on most relevant queries in your specialism. A citation rate of 10 to 20 percent is the range where you start seeing meaningful referral traffic from AI-cited sources. Sentiment should skew positive or neutral. Consistent negative framing at this scale is worth investigating. It usually traces to a specific piece of content, a review profile, or a competitor comparison page that the models are treating as authoritative.
Category leader (dominant brand in a defined UK niche). A mention rate above 60 percent on category prompts and a citation rate above 25 percent are the thresholds where LLM visibility starts to act as a genuine pipeline driver. The third signal at this level is named-entity consistency: the models should be associating your brand with specific, positive positioning, not just your category name. If ChatGPT mentions you but associates you with nothing in particular, the brand is present but not owned.
The gap between small business and category leader is large, and working up these thresholds is a multi-quarter effort. The value of establishing a baseline is not that it tells you where you should be. It tells you whether you are moving. In a metric this new, that is the only meaningful question.
Our AI SEO agency team tracks and improves LLM visibility for UK service businesses across all three of these tiers. We can tell you exactly where your brand sits before you commit to any improvement work.
From measurement to improvement: the optimisation loop
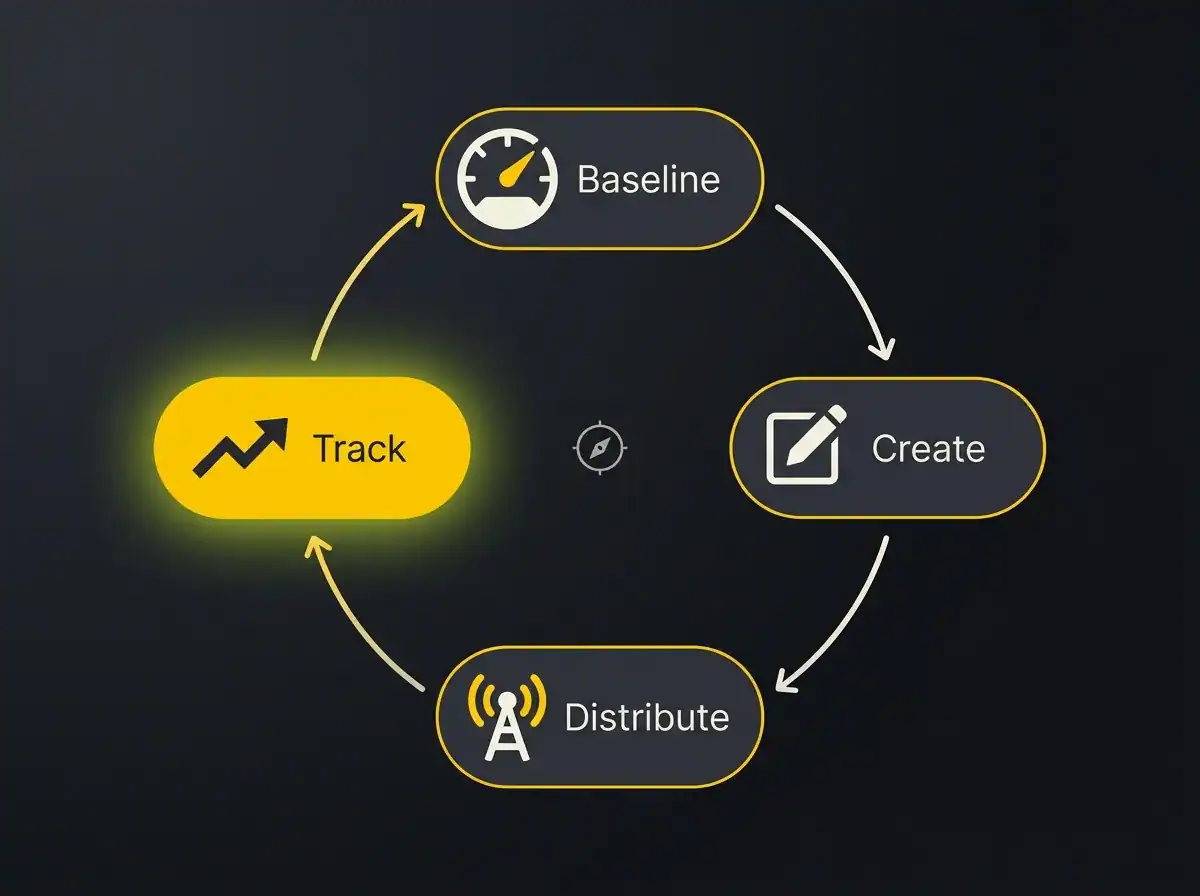
Once you have a baseline score and understand which of the five metrics needs moving, the work has a clear shape. It is not SEO. The instinct to build links and update technical settings is mostly wrong here.
Citation building is closer to PR than link building.
The four things that shift LLM visibility scores over time are content structure, named-entity presence, source reputation, and consistency.
Content structure means writing pages that give models something atomic to cite. A page that makes one precise claim in plain English, defines a term clearly, and answers a specific question directly is more citable than a page that makes five broad claims in polished prose. Clear definitions, FAQ schema on relevant pages, and structured headers that tell the model what a section is about all help. The improvement is gradual but compounding.
Named-entity presence means appearing consistently alongside the right terms, topics, and people in your category. If your brand name shows up repeatedly next to the problem descriptions, category terms, and named concepts in your space, models build stronger associations between your name and your positioning. Vague brand positioning creates vague model associations. Specific positioning creates specific ones.
Source reputation means earning mentions and citations on the platforms and publications that LLMs treat as authoritative for your sector. That typically means industry publications, recognised directories, and credible community spaces that surface reliably when the models retrieve live results. This is earned-media work, not technical work.
Consistency means tracking monthly rather than weekly. LLM scores move slowly because model training and retrieval updating happens on cycles measured in weeks or months. Checking daily or weekly creates noise, not signal. A monthly tracking cadence with a 90-day trend review is the rhythm that works.
Frequently asked questions
How is LLM visibility different from SEO visibility?
SEO visibility measures where your pages appear in a list of search results and how often they earn a click. LLM visibility measures whether your brand name appears inside an AI-generated answer, across ChatGPT, Claude, Perplexity, Gemini, and Google AI Overview. The two metrics can move independently. Strong Google rankings do not guarantee AI presence, and a brand can earn meaningful AI citations from pages that perform modestly on traditional search. They require different inputs and different tracking approaches.
Do I need a paid tool to track LLM visibility?
No, not at small business scale. A manual tracking workflow running a fixed set of 25 to 30 prompts across the major models once a month, logged in a spreadsheet, costs a few hours and the price of a Plus subscription you probably already have. Paid tools add value when you need continuous monitoring, automated competitor benchmarking, or coverage across more models than you can track manually. For a first baseline, and for ongoing tracking at a business with under roughly £2 million in revenue, manual tracking is the sensible starting point.
What is a good LLM visibility score?
It depends on your scale and category. A small UK service business should aim for a 15 to 25 percent mention rate on a 30-prompt category set, with any citation rate above five percent being meaningful at that scale. A mid-market business should be working towards 35 to 55 percent mention rate and 10 to 20 percent citation rate. These are CT heuristics from recent audit work, not published industry benchmarks. Mature benchmarks for this metric do not yet exist, which is why having your own baseline matters more than comparing to an abstract industry average.
How often should I track LLM visibility?
Monthly is the right cadence for most UK service businesses. LLM scores move slowly because model training and index updating happens on cycles measured in weeks or months, not days. Weekly tracking generates noise rather than signal. A monthly check with a quarterly trend review gives you the data you need without creating busywork from normal week-to-week variation.
Does LLM visibility actually drive enquiries?
Indirectly and increasingly. A citation with a link drives referral traffic, and that traffic tends to convert well because visitors arriving via an AI recommendation have already received an endorsement. The connection between name mentions without links and direct enquiries is harder to measure, though consistent brand presence in AI answers builds familiarity that influences buyers who later search directly. As AI traffic converts at a significantly higher rate than traditional search, improving citation rate is the highest-value sub-metric to focus on first.
How CT helps service businesses track and improve LLM visibility
If you have read this far and want to know where your brand actually stands, the fastest next step is the AI Visibility Audit.
Free resource: AI Visibility Audit
The audit runs your brand and up to three named competitors through a fixed prompt set across ChatGPT, Claude, Perplexity, and Gemini. It returns a mention rate, citation rate, sentiment breakdown, and source analysis showing which pages and domains are driving your current AI presence. It takes around 48 hours and costs nothing. The output tells you exactly where you are starting from and which of the five metrics to prioritise first.
If you already have a number and want delivery rather than diagnosis, our AI SEO agency team works with UK service businesses on the full improvement programme: content restructuring, named-entity work, source development, and monthly tracking against a defined benchmark.
LLM visibility is a metric you can act on this quarter. The brands that establish a baseline now will have a compounding advantage as AI search adoption keeps growing. The ones that wait will be tracking a gap that has already widened.
