
The reason ChatGPT doesn't mention your business has nothing to do with ChatGPT.
Or Perplexity, or Claude, or Gemini. They're all drawing from the same underlying source. And that source isn't something you fix by tweaking your social media presence or publishing more blog posts.
You've probably heard the terms "knowledge graph" and "entity SEO" at some point. Maybe your agency mentioned them. But most of what's been written about this topic either explains the concept in general terms, or tries to sell you a tool that builds you a private version of one. Neither actually tells you what to do on your own website, in your structured data, and across the open web to get your business recognised as a verified entity.
That's what this article covers. What the knowledge graph is, why it now determines whether AI tools include you in their answers, and what you can practically do about it if you run a UK service business.
The 60-second answer
Knowledge graph SEO is the practice of structuring your website, your structured data, and your off-site references so that search engines and AI models recognise your business as a verified entity rather than a string of text.
Google built a Knowledge Graph to move from matching words to understanding things: businesses, people, places, events and the relationships between them. ChatGPT, Claude, Perplexity and Gemini all draw on entity-rich data, including the same sources Google uses, such as Wikidata, Wikipedia and the Common Crawl. When an AI is asked to recommend a business or answer a question about a company, it looks for entities it can verify.
The practical work covers four areas: schema markup on your website (specifically Organization, Person and Service schema with sameAs links), consistent entity references across authoritative sources, a Wikidata record for your business, and content that names your entity clearly and repeatedly. None of it requires a third-party tool. All of it compounds over time.
What the knowledge graph actually is (and why entities beat strings)

For most of its history, Google treated search queries as strings of text. You typed "david bowie" and Google went looking for pages that contained those two words. It worked well enough. But it was fragile, and it could not answer complex questions about the world because it had no model of the world, only a model of documents.
The Google Knowledge Graph, launched in 2012, was an attempt to fix that. Instead of just indexing documents, Google started building a structured map of entities: things in the world, their properties, and the relationships between them. "David Bowie" stopped being a string of words and became a person entity, with properties (musician, British, born 1947, genre rock) and relationships to other entities (Tin Machine, Mick Jagger, Iman).
The same logic applies to businesses. Your company is either an entity, meaning a thing Google has a structured record for with verified properties and relationships, or it is a string of text that happens to appear on various web pages. The difference between the two determines whether Google can confidently surface information about you, and whether AI tools can mention you in response to a question.
This is not a new idea. Wikipedia and Wikidata have been organising knowledge this way for decades. What is new is that the same entity layer that powers Google now powers the AI tools your customers are using to find recommendations.
Solid technical SEO foundations are what make entity work stick. Without a well-structured site, consistent on-page signals, and proper internal linking, even the best schema markup lands on shaky ground.
Why knowledge graph SEO now matters more for AI search
Here is the thing most AI search advice misses. ChatGPT, Claude, Perplexity and Gemini do not have their own independent records of every business in the world. They were trained on large datasets that include web crawls, Wikidata, Wikipedia and authoritative third-party sources. When they generate a response mentioning a specific company, they draw on the entity signals baked into that training data, plus, in the case of retrieval-augmented systems like Perplexity, live crawls of the current web.
What that means in practice: if your business exists as a clearly verified entity with consistent signals across the open web, AI tools can mention you confidently. If it exists only as a name on your own website, with no structured data, no Wikidata record and no meaningful third-party citations, AI tools will either ignore you or confuse you with a similarly named business elsewhere.
This is part of why AI search traffic converts at significantly higher rates than traditional search. People who arrive via an AI recommendation have already been through a verification step. The AI has decided you are credible enough to mention. That credibility starts at the entity layer.
Google's AI Overview adds another dimension. For informational searches in the UK, an AI Overview now often appears above the organic results. The content it cites is pulled from pages Google has already categorised as authoritative on the entity being discussed. Getting into that citation layer means building entity authority, not just page authority.
The Knowledge Panel is a symptom, not the goal
A lot of businesses come to this topic with the same mental model: knowledge graph SEO means getting a Knowledge Panel. The one that appears on the right side of Google with your logo, a description and your founding date.
That's a reasonable thing to want. But it's the wrong thing to target.
A Knowledge Panel is what Google displays when it is sufficiently confident about an entity to show structured information about it. It is a downstream output of the entity work having been done properly. When the schema markup is right, the Wikidata record exists, the authoritative citations are consistent, and the content is sufficiently clear about what the entity is, a Knowledge Panel often follows. Sometimes it doesn't, particularly for smaller businesses where the public interest threshold has not been crossed. That is fine.
Targeting the panel itself leads to a specific mistake: claiming a Google Business Profile and calling the entity work done, or adding a directory listing and assuming the job is finished. Neither gets you into the Knowledge Graph in any meaningful sense. The Business Profile is a separate system. The entity layer is the underlying structure.
The goal is entity recognition. The panel, if it appears, is confirmation you got there.
What entity SEO looks like on your own site
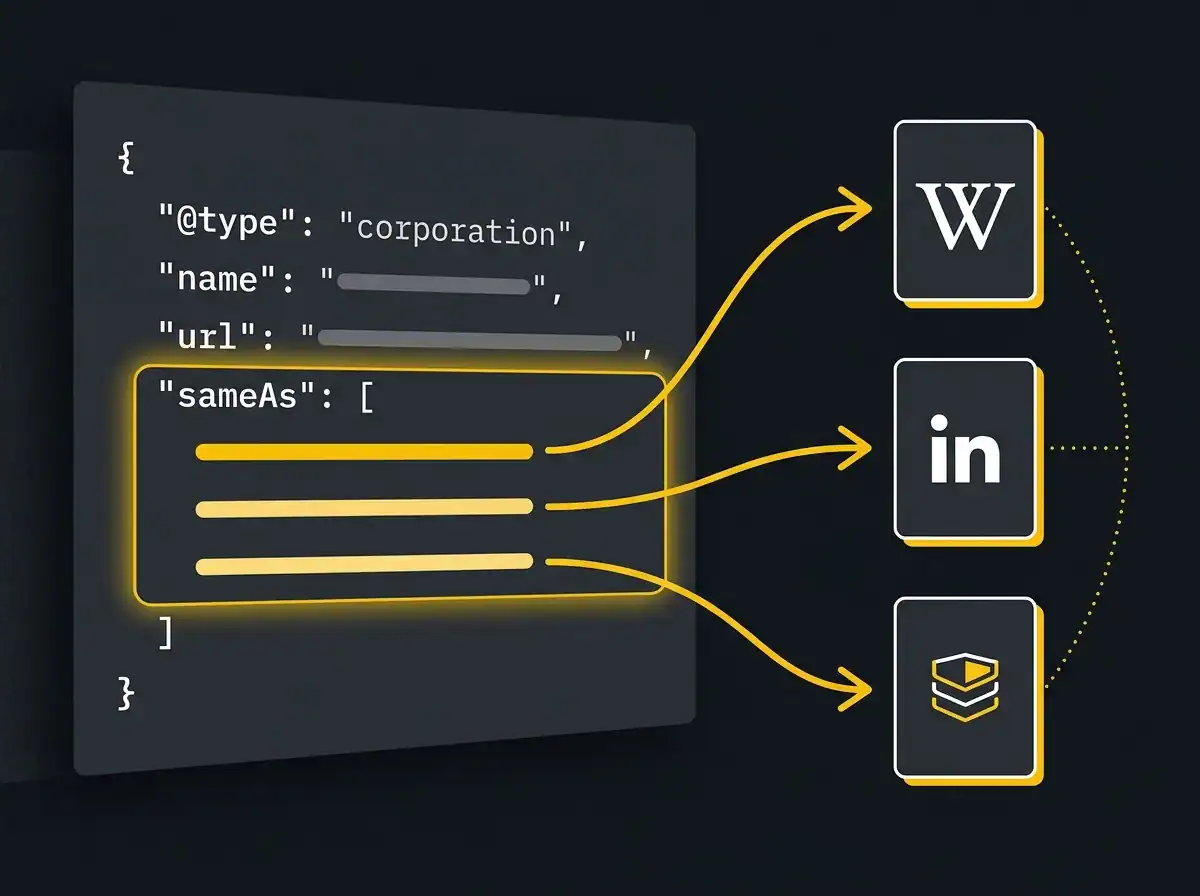
This is where the practical work lives. Four types of schema markup matter most for a UK service business, and all of them should be implemented as JSON-LD in the head of your pages, using vocabulary from schema.org, the shared standard backed by Google, Microsoft, Yahoo and Yandex.
Organization schema is the foundation. It tells search engines and AI tools what your business is, where it is, how to reach it, and where else on the open web it is authoritatively listed. The sameAs property is critical here. It links your schema to your Wikidata item, your LinkedIn company page and your Companies House record. That triangle of verification is what moves you from a string to an entity.
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "Example Ltd",
"url": "https://www.example.co.uk",
"logo": "https://www.example.co.uk/wp-content/uploads/logo.png",
"address": {
"@type": "PostalAddress",
"streetAddress": "12 High Street",
"addressLocality": "London",
"postalCode": "EC1A 1BB",
"addressCountry": "GB"
},
"telephone": "+44-20-1234-5678",
"sameAs": [
"https://www.linkedin.com/company/example-ltd",
"https://www.wikidata.org/wiki/Q12345678",
"https://find-and-update.company-information.service.gov.uk/company/12345678"
]
}
Person schema for founders and key team members is the second piece. Author credibility matters both for Google's E-E-A-T evaluation and for AI tools that try to determine whether content comes from a real, named person with a verifiable professional history.
{
"@context": "https://schema.org",
"@type": "Person",
"name": "Jane Smith",
"jobTitle": "Managing Director",
"worksFor": {
"@type": "Organization",
"name": "Example Ltd"
},
"url": "https://www.example.co.uk/about/jane-smith/",
"sameAs": [
"https://www.linkedin.com/in/jane-smith-example",
"https://www.wikidata.org/wiki/Q87654321"
]
}
Service schema belongs on each individual service page. FAQPage schema belongs anywhere you answer questions directly. Article schema, with author markup pointing to a real Person entity, belongs on every blog post.
Beyond schema, three structural things matter equally. Every time you mention a service or a team member in your content, that mention should link to the canonical page that describes that entity. Your About, Team and Contact pages need to function as the source of truth for your entity facts: if your About page says the company was founded in 2010 and your LinkedIn says 2012, you have inconsistent entity signals. Pick one and standardise everything. The name you use for your business should be identical across your website, your social profiles, your schema, your Wikidata item and every directory you control.
You can check whether your schema is being read correctly in Google Search Console, under the Enhancements section, which flags any structured data errors Google has found during crawl.
For businesses that want this work done systematically, an AI search agency can audit your current entity footprint and build out the schema and off-site signals in a structured programme.
The off-site half of knowledge graph SEO
On-site schema is necessary but not sufficient. What gives it credibility is the network of third-party references that corroborate it.
Wikidata is the most important single off-site asset for entity verification. Unlike Wikipedia, Wikidata does not apply the same notability threshold. Most established businesses can create a Wikidata item without needing a Wikipedia article to justify it. A basic item for a UK company should include the entity type (instance of: business), name, website, Companies House registration number, founding date, founder, headquarters location and industry classification. Once the item exists, you add its URL to the sameAs list in your Organization schema, and the bidirectional verification loop is closed.
Authoritative citations are the second layer. A mention of your business on a .gov.uk domain, in a trade press article, in an industry body membership directory or in a professional register (CQC, FCA, SRA, ICAEW depending on your sector) carries meaningful weight. These are the sources that Wikidata editors use to verify items, and they are the sources LLMs were trained to treat as credible.
Consistency is the discipline that ties all of it together. Your business name, address, phone number, founding date, founder name and description of what you do should be identical across every authoritative source. Even small discrepancies (a slightly different trading name on one directory, an old address still live somewhere) introduce noise into the entity signals and make AI tools less confident about mentioning you.
The Common Crawl is worth understanding. It is a publicly available archive of web pages used to train most of the major LLMs. The citations your business collects in high-trust sources are being crawled now and will seed the training data for the next generation of AI models. The entity work you do today compounds into AI visibility over the following 12 to 18 months. It is not a quick win. It is foundational.
How to check whether your business is in the knowledge graph
Three tests give you a clear read on where you currently stand.
The first is the Knowledge Panel test. Search for your business name in Google from a UK browser. If a panel appears on the right with your logo, description and business details, Google has an entity record for you. If nothing appears, or if what shows is only a Map Pack result from your Google Business Profile, the entity work has not landed yet.
The second is Google's Knowledge Graph Search API. It is free to query if you have a Google Cloud account, and it lets you search the actual entity database directly. Query your business name and look at the response. If Google returns a structured entity result with a MID (Machine ID, formatted like /m/abc123), you are in. If the query returns nothing, or returns only results for businesses with similar names, you are not. Developers call this the kgsearch API, and it is the most direct signal available outside of the Knowledge Panel itself.
The third test is the AI prompt test. Open ChatGPT, Claude and Perplexity and ask each one: "Tell me about [your business name]." Note what they say, what they get wrong and whether they confuse you with another business. This is the quickest practical read on whether your entity work is translating into AI visibility.
Free resource: AI Visibility Audit
If you want a structured read on what AI tools currently say about your business and what entity work would change that, the AI Visibility Audit gives you exactly that in one document.
Common mistakes (and what to do instead)
The most common mistake is treating the Knowledge Panel as the goal. Businesses spend time trying to claim or trigger a panel, or report it as an objective to their agency. The panel is a side effect. Do the entity work properly and it often appears. Optimise for the panel directly and you end up taking actions with no structural impact underneath them.
The second is cargo-cult schema markup. This means adding every schema type the validator allows, whether or not it describes what actually exists on the page. Product schema on a service business. Event schema because someone read a tutorial. Review schema on a page with no verified reviews. Stick to schema types that genuinely describe the entity. An over-structured site with inaccurate schema sends confusing signals, not strong ones.
The third is inconsistent entity references across the web. A business that trades as "ABC Consulting" on its website, "ABC Consulting Ltd" on LinkedIn, "A.B.C. Consulting" on a trade directory and has no Wikidata record is presenting four different entities that might or might not be related. The Knowledge Graph does not resolve that ambiguity in your favour. Pick the canonical name, standardise everything, then build outward.
The fourth is hiring an agency that talks about schema markup but has nothing to say about Wikidata, citation building or AI prompt testing. Schema is the starting point, not the complete picture. Any serious entity programme includes the off-site verification layer and a regular check of what the AI tools are actually saying about you.
Where this fits in a wider AI search programme
Knowledge graph SEO is the entity layer. It is foundational work that makes everything else more effective.
But entity work alone does not complete the picture. AI search visibility also requires strong, citable content that AI Overview and LLM retrieval systems want to lift, a well-structured site that signals topical authority, and increasingly, an llms.txt file that guides AI crawlers to the pages most relevant to your business. The entity layer establishes that you exist and what you are. The content layer establishes what you know and what you are best placed to help with.
Both sides of that belong in a proper search visibility programme that treats traditional search and AI search as the same audience arriving via two different doors.
If you want to see what ChatGPT, Claude and Perplexity currently say about your business and what entity work would change that, the AI Visibility Audit gives you that in one document. It is the cheapest piece of AI search visibility most UK businesses are not yet doing.
And it compounds.
